
自主创新之路再立丰碑
日前,由同方鼎欣和清华大学信息技术研究院语言和语音实验室合作研发的『一种非汉语语音识别方法、系统及其构造方法』荣获国家发明专利权(专利号:201710156620.8)。
该发明填补了国内在语音识别系统领域的一项技术空白,这项技术具备深厚的人工智能信息技术的积淀和创新内涵,并且有潜在较大的商业应用前景,将持续产生显著的社会和经济效益!
聊点专业的:专利内容解析
『一种非汉语语音识别方法、系统及其构造方法』基于跨语言因子对日语声学模型进行增强,能够高效地进行大数据训练从而构建基于神经网络的声学模型;能够对正确标注的大量日语语音数据进行解析,通过收集大量文本资源进行语言处理,生成识别解码器,从而对输入语音进行语音解码结果评判。
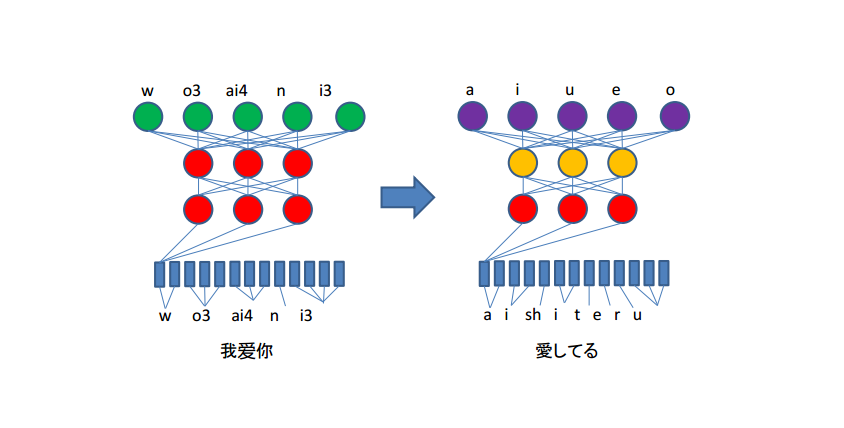
本专利结合对于日语自然语言处理、日语词库建设、日语文本分词手段等多种技术和非技术因素的综合考虑,运用了人工智能领域的主流成熟的深度学习和大数据处理等多项核心技术,技术要素比较繁多,技术难度比较高。
l 在实施商业项目前期调研分析了科研和产业界的多种语音识别技术框架和多项技术手段,并比照分析研究了许多新的技术手法和算法;
l 采纳语音领域主流框架Kaldi,广泛消化和吸收了其所带来的先进概念、设计和算法,融合了业界一些有用的跨语言技术;
l 借鉴现有中文语音识别的模型资源,利用跨语言因子技术,对资源较为匮乏的日语语音语言资源所训练的声学模型进行增强。
从而实现可基于相对较少的日语数据资源可以有效地训练日语语音识别系统的神经网络模型,并继承汉语模型对噪声和口音的鲁棒性,提升系统实用性能。
此专利应用于提升既有机器人处理日语自然语言、语音、机器会话、自然语言对话系统等水准,升级现有产品的语音语言处理的人工智能技术水平。
课代表总结:本发明提出并实现了一种利用既有的中文语音资源及其训练出的模型实现知识转移,使得可以利用相对少量必须的日语数据资源就可以快捷地构造出有效的日语语音识别系统的方法。以此为基础进一步可基于小数据资源和低算力资源条件下构建特定语言的语音识别系统,因而本项专利实现具有很高的技术价值和商用价值。
由于利用知识转移手法采取既有的汉语语音识别技术的经验和吸纳有关技术,研发团队在实施日语的语音识别项目研发时,避免了很多不确定性因素和开发弯路,有效运用了宝贵的算力资源;在针对各个技术环节特别是模型参数选择等的尝试验证和组合验证的效率上有了极大的提升和改善。
一项专利 可观效益
语音识别引擎系统的开发是当前人工智能领域热门的技术话题之一,特别是国内针对日语做语音识别的成功案例不多。任何一个人工智能项目的建设前期依赖于丰富的资源建设,依赖于强大的算力资源支持从而训练生成高效的神经网络系统,后期则是在良好和高效的模型引擎基础上进行业务系统的应用开发。
目前市面上还缺乏既被广泛认知又适用于特定语种语言,特定行业业务运用的高度AI技术的语音识别商用系统,因此本发明在实施过程中积累的技术经验可以在未来持续带动符合用户需求的语料资源建设加工,以及与同样来源于语音信号的声纹技术、自然语言的情感技术、多轮对话系统等结合起来,通过这些技术的连动和集成,相辅相成,进一步推动和开拓技术的深度与广度,灵活地运用于产业和服务机器人等综合性的应用系统和产品开发中。
该发明在方兴未艾、群雄纷争的人工智能发展潮流中为同方鼎欣争得了一席之地。既有利于为公司进一步拓展海内外市场,带来相应的经济效益,更能为人工智能时代的信息产品增添亮眼的新技术,助力行业和科技发展。
——·——
同方鼎欣将以此发明专利证书的获得为契机和动力,加大对人工智能相关技术的投入和开拓,实施和语音有关的声纹识别、计算机自然语言理解、智能会话以及从日语到中文等多语种的语音识别等技术,实现在国内外多业务上的应用。
未来,公司将进一步完善知识产权保护体系,发挥自主知识产权优势,并形成持续创新机制,提升公司的核心竞争力,以自主创新技术为多领域客户提供更高端、更专业的IT服务。
 京公网安备 11010802024764号
京公网安备 11010802024764号